How we built offline-first without losing the team's sanity
Building a true offline mode for healthcare equipment teams meant rethinking sync conflicts, data integrity, and what "saved" really means.
Nº 2
8 min read
Five seconds, then back to work.
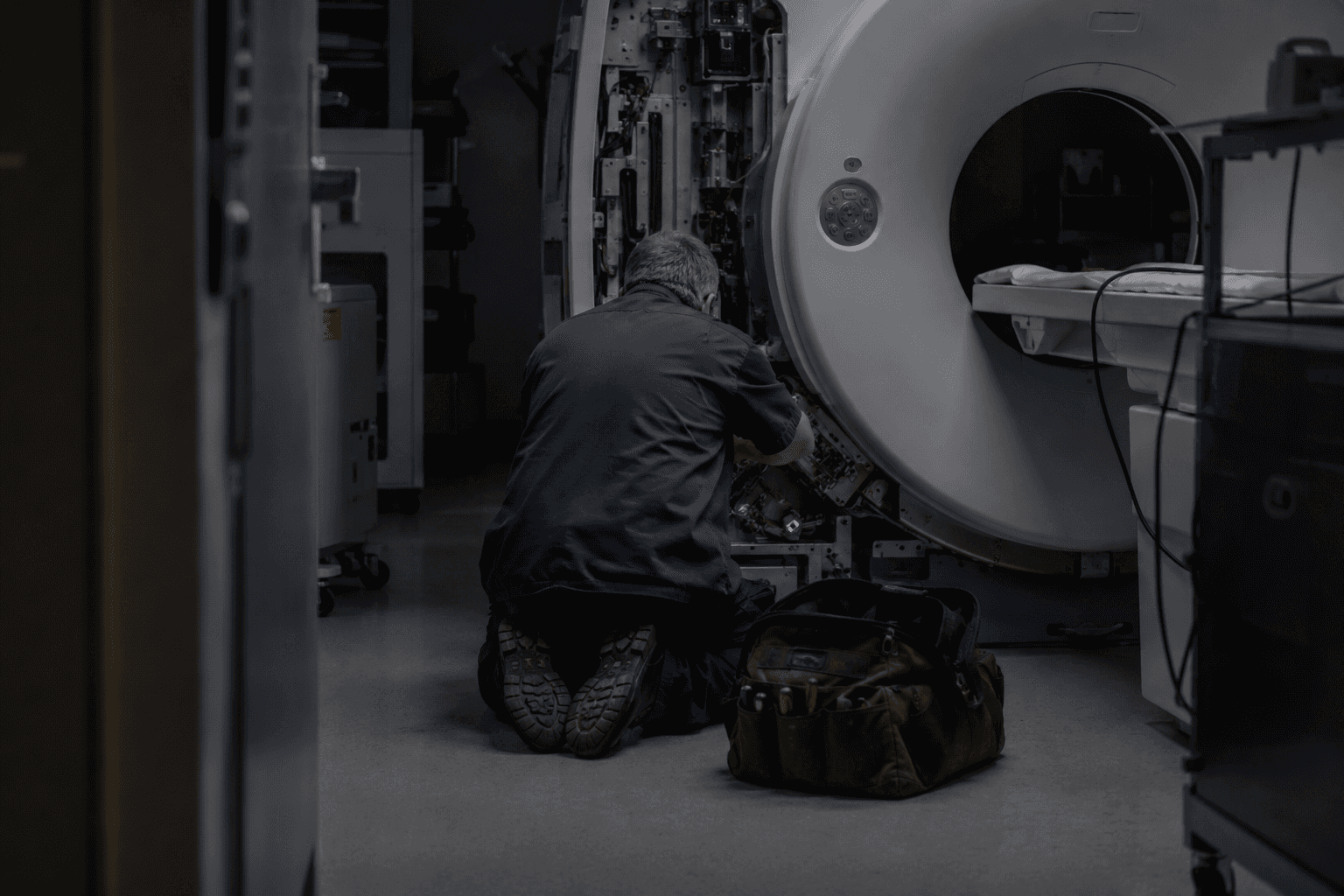
There is a room in almost every hospital where mobile software goes to die.
It is usually in the basement. It is usually next to an autoclave or an MRI suite, behind a door with a radiation symbol on it, and it has zero bars of signal. This is, unfortunately, also where some of the most important service work happens.
When we started building Mediora, we made a product decision early on that shaped almost everything that came after it: the mobile app had to work there. Not "work with reduced functionality." Not "queue actions and warn the user." Work — fully, silently, as if the internet had never been invented.
This is the story of how we got there, and how many times we almost gave up on the way.
Why "offline support" is not the same as offline-first
Most apps that claim offline support are lying, a little. What they mean is: if you lose signal while filling out a form, we won't throw it away. The data sits somewhere and tries to sync when you reconnect. This is polite. It is not sufficient.
A technician servicing a CT scanner in a hospital sub-basement is not just "losing signal for a moment." They might be disconnected for two hours. They might pick up a job that was assigned to a colleague at 8am, work through the morning without reception, complete three service calls, and reconnect at lunch. During that time, the same device records they're writing to might have been touched by a service manager, an admin, and another technician working from a different hospital.
Handling one offline write is a UX problem. Handling three hours of parallel offline writes, across multiple users, on shared records, in a domain where data integrity is a regulatory requirement — that is an architecture problem.
We had been treating it as the first kind for too long.
The three questions that broke us, then fixed us
At some point in late 2023 we sat down and forced ourselves to answer three questions plainly, without the softening language that product teams use to avoid committing to hard things.
One: what is the unit of truth?
In a fully connected system this is easy — the server is the truth. In an offline-first system, the device is the truth during disconnection, and the server is the truth afterward, and you need a principled rule for what happens when those two truths contradict each other.
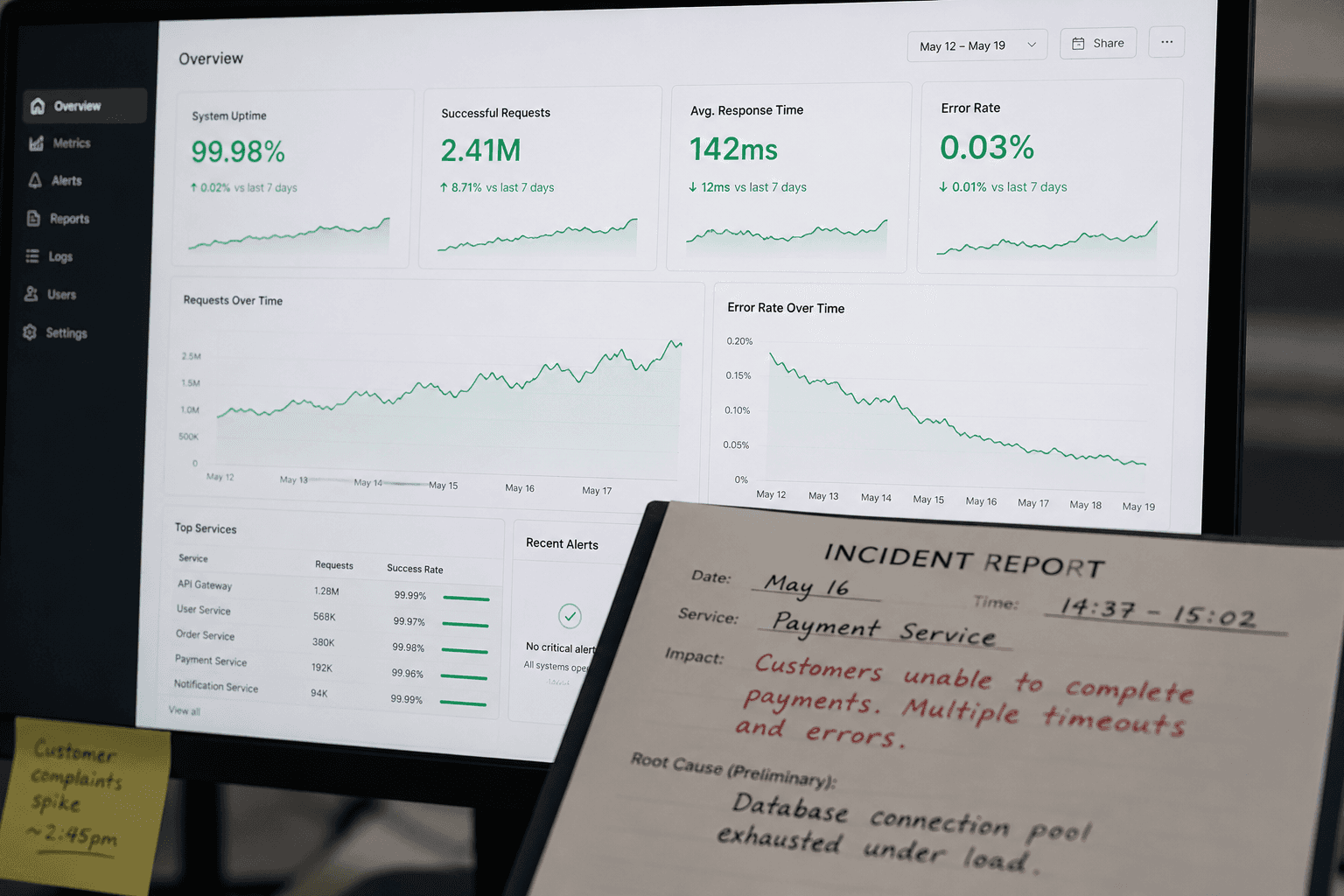
We had been using a last-write-wins approach, which is fine for most consumer apps. It is not fine when "last write" means a technician's field notes from 10am might silently overwrite a parts replacement record that a colleague added at 10:15am. In medical equipment servicing, that's not a data conflict — it's a compliance problem.
We moved to operational transforms — tracking not just the final state of a record but the individual field-level changes, with timestamps and authorship, and merging those changes rather than replacing them. It took three weeks and two rewrites. It was worth it.
Two: what does "saved" mean?
This sounds philosophical. It is also deeply practical.
When a technician taps the save button, several things could be true: the record is saved locally only; the record is saved locally and queued for sync; the record is synced to the server; the record is synced and confirmed. These are four different states. Most UIs collapse them into one checkmark and a word, which trains users not to trust the word.
We ended up with an explicit sync status indicator on every record — not a spinner, not a vague cloud icon, but a small, honest label. "Saved locally. Will sync on reconnect." "Synced." "Conflict — tap to review." It added visual complexity we didn't love. It built trust we couldn't have gotten any other way.
One of our early customers — a service team lead with twelve technicians across six hospitals — told us in a feedback session: "The first time I saw 'saved locally' on a record, I almost uninstalled the app. The tenth time, I stopped worrying about signal entirely." That arc was intentional. We wanted people to go through it.
Three: who resolves conflicts, and when?
The honest answer to this question is: not automatically, and not immediately.
There is a temptation in systems design to resolve everything without bothering the user. Merge silently, pick the most recent, infer intent. This works for notes in a consumer app. It does not work when the conflict is between "parts replaced: none" (written offline this morning) and "parts replaced: coil assembly, 3 units" (written by a colleague while the first technician was underground).
We built a conflict review queue. When a sync surfaces a genuine conflict — same field, different values, no obvious resolution — it does not resolve it. It creates a task for the relevant service manager, shows them both versions with context, and waits. The service manager resolves it once, and the resolution is logged.
No user has ever thanked us for making them resolve a conflict manually. Several have told us it prevented an incident report.
The technical architecture, briefly
We won't go deep here — a proper writeup is coming — but for those keeping score:
Local-first data layer: every device maintains a full replica of the records it has permission to access, updated incrementally via a sync protocol.
Conflict detection: field-level change vectors with logical timestamps (not wall-clock time, which is unreliable on mobile).
Sync queue: outbound changes batch and compress before transmission; priority ordering means critical writes (job completions, parts records) sync before background metadata.
Optimistic UI with honest state: the interface responds to local writes immediately, but surfaces real sync state clearly rather than hiding it.
The part that cost us the most time was not the sync protocol. It was the test infrastructure. Testing offline scenarios means simulating intermittent connectivity, deliberate conflicts, partial syncs, and device clock drift simultaneously. We built a fake network layer that could inject all of these on command. It is, genuinely, the most useful engineering tool we have.
What we got wrong the first time
Two things, mainly.
We under-estimated the diversity of disconnection.
There are at least six different failure modes between "full signal" and "truly offline": weak signal, captive portals, hospital Wi-Fi that connects but throttles to unusable speeds, VPN authentication timeouts, and more. Our first offline implementation handled zero bars well and handled everything else badly. The fix was to stop asking "are we online?" and start asking "can we actually complete this write?" These are different questions with different answers.
We over-engineered the conflict UI.
The first version showed technicians a diff view — old value, new value, who changed what, when. Three columns. Timestamps. It was complete and impossible to use quickly in a hospital corridor. We stripped it back to a single question with two options and a "see full history" link for people who wanted it. Usage went up. Conflicts got resolved faster.
What "offline-first" actually gave us
The signal quality problem is real, but it is not the most important thing offline-first solved for us.
The more important thing is that it changed the trust relationship between the software and the people using it. A technician who knows their work is safe — regardless of signal, regardless of what else is happening in the system — works differently. They stop double-checking. They stop taking photos of their screen as backup. They stop paper-logging "just in case." They trust the tool, and the tool earns that trust by being predictable.
One metric we track is re-open rate: how often a user opens a record they already saved, just to verify it's still there. When we launched the explicit sync status labels, re-open rate dropped by 40% over six weeks. That is forty percent fewer interruptions to workflow. Forty percent less latency introduced by doubt.
That number, more than any sync performance benchmark, is the one we're proud of.
What's next
We are currently rebuilding the sync engine to handle team-level operational contexts — situations where a whole team goes offline together (a hospital network outage, a site visit to a remote location) and comes back online simultaneously. The current architecture handles individual disconnections well. Coordinated reconnection at scale is the next problem.
We expect to break things at least twice in the process.
We will write about it when we're done.
Share

about the author
Sofia Lindqvist
Co-founder & CTO
Writes about engineering, infrastructure, and the slow craft of designing software that ages gracefully.
Continue reading
More from the same beat — operations, equipment, and the slow business of building reliable software.